Obsahová analýza (anglicky content analysis) je analýza, zkoumající povahu obsahu a jeho charakteristiku. Zabývá se tedy jak strukturou a rozsahem textu, tak jeho stěžejními body, identifikací autora, čitelností a mnoha dalšími prvky.
V oblasti online marketingu se většinou obsahová analýza týká konkrétní sekce obsahu webových stránek, které doporobna rozebírá a identifikuje jejich slabá/silná místa, případně navrhuje, jakým směrem se při psaní dalšího obsahu ubírat.
Data k obsahové analýze z Marketing Mineru
Miner Obsahové analýzy vám pomůže s analýzou vašeho vlastního obsahu, ale klidně i s analýzou obsahu vaší konkurence. Zjistěte informace o meta datech (titulky, popisky) jednotlivých URL, ale také o počtu slov či počtu odkazů na dané URL.
Využití v praxi
Obsahová analýza vlastního webu
Při obsahové analýze vlastního webu vás bude zajímat například:
- Titulek – Není titulek příliš dlouhý nebo naopak příliš krátký? Obsahuje klíčové slovo a je atraktivní pro uživatele, který vyhledává přes Google?
- Meta popisek – Není popisek příliš dlouhý nebo naopak příliš krátký? Obsahuje klíčové slovo a je atraktivní pro uživatele, který vyhledává přes Google?
- Nadpis H1 – Obsahuje H1 klíčové slovo? Vystihuje H1 podstatu dané stránky a je atraktivní pro uživatele?
- ALT text – Kolik obrázků z celkového množství na stránce nemá vyplněný ALT text.
Obsahová analýza konkurenčního webu
I při obsahové analýze konkurence se můžete zaměřit na titulky, popisky a H1 nadpisy. Především proto, abyste zjistili, na jaká klíčová slova vaše konkurence optimalizuje, jaký obsah vytváří a v kombinaci s Minerem Sociální signály určili, které z těchto článků jsou nejúspěšnější na sociálních sítích.
Kromě toho se můžete podívat i na jiné metriky, například:
- Počet slov na URL.
- Počet interních a externích odkazů na dané URL.
- Průměrný čas čtení daného článku.
Pojďme si ukázat, jak jednotlivá data získáte.
Vložení vstupních dat
Začněte tím, že na úvodní stránce kliknete na Vytvořit report a na vstupu zadáte URL. Následně na vstup napíšete nebo zkopírujete seznam URL, u kterých chcete analyzovat obsah.
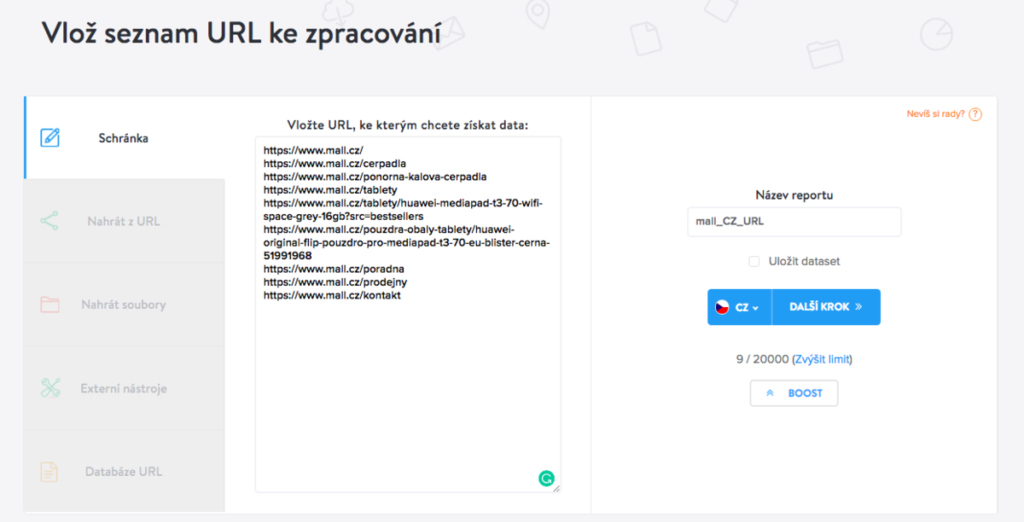
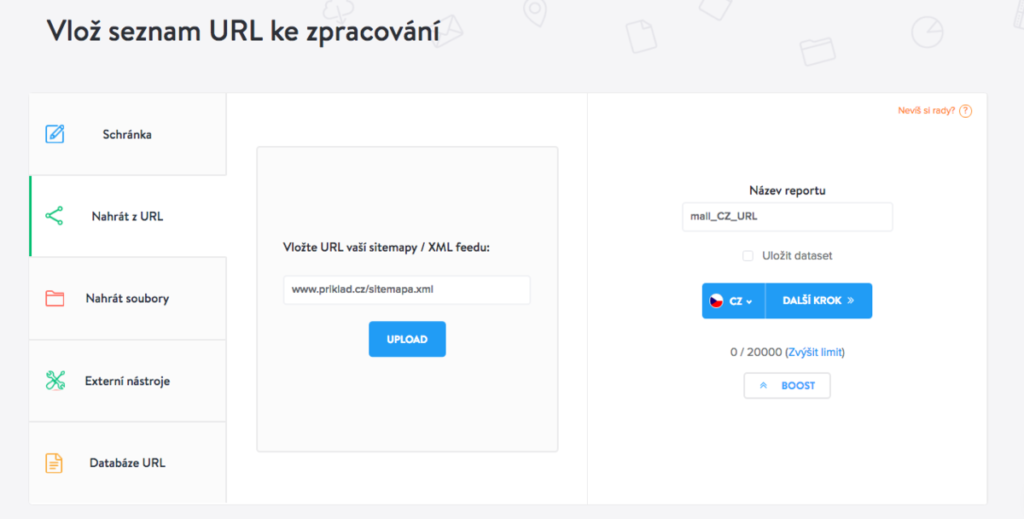
Ještě lepší variantou by však bylo vložit celou sitemap webu, pokud ji máte k dispozici. To uděláte tak, že se v levé části vstupního boxu prokliknete na sekci Nahrát z URL.
Aby byl váš report jednoduše identifikovatelný, je dobré ho pojmenovat. Stačí kliknout na pole Název reportu.
Následně stačí kliknutím na vlajku vybrat zemi, pro kterou chcete získat data. Po kliknutí na Další krok se dostáváte na volbu Mineru.
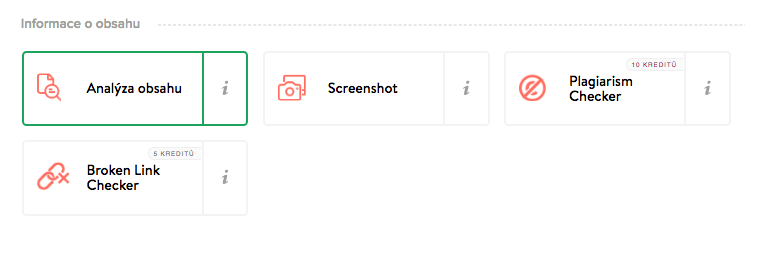
Volba Mineru
V sekci Informace o obsahu klikněte na Miner Analýza obsahu. Nic dalšího není potřeba nastavovat. Pokračujte kliknutím na tlačítko Získat data.
Ukázka výstupu
Ve výstupu uvidíte pouze prvních 200 záznamů z celkového počtu URL. Proto doporučujeme výstup stáhnout ve formě Excelu a následně analyzovat výsledky přímo tam.
Popis sloupců
V Marketing Mineru jsou sloupce rozděleny do dvou záložek. V Excelu je najdete všechny pohromadě. Pojďme si vysvětlit, co znamenají.
Content
- Input: vložená URL adresa na analýzu.
- Status: Stav analyzované URL. Pokud by bylo na dané URL přesměrování nebo chyba, bude ve sloupci zobrazen stavový kód přesměrování nebo chyby. Více o stavových kódech najdete v návodu Kontrola stavových kódů a přesměrování.
- Meta description: Meta popisek stránky.
- H1: Hlavní nadpis stránky.
- Title: Titulek stránky.
- Title width: Délka titulku v pixelech.
- Number of images: počet obrázků nacházejících se na dané stránce.
- Images without alt text: počet obrázků, které nemají vyplněný ALT text.
- Number of videos: počet videí na stránce.
- Number of tables: počet tabulek na stránce.
- Comments: Počet komentářů k článku.
Statistics
- Input: vložená URLadresa na analýzu.
- Reading Time: Přibližná doba čtení obsahu na dané URL. Je vypočtena na základě počtu slov v obsahu.
- Words: Počet slov na dané URL.
- Paragraphs: Počet odstavců v obsahu dané URL.
- Links: Počet interních a externích odkazů na dané URL.
- Number of external links: Počet externích odkazů na dané URL.
- Number of internal links: Počet interních odkazů na dané URL.
- Rel=”next”: Uvádí, zda je někde v obsahu označení následující stránky pomocí rel = “next”.
- Rel=”prev”: Uvádí, zda je někde v obsahu označení předcházející stránky pomocí rel = “prev”.
Analýza výstupu
Při analýze vlastní stránky se zaměřte na analýzu titulků, popisků a H1 nadpisů.
Optimalizace titulků
Příliš dlouhé titulky (nad 600 px) vám Marketing Miner ve výstupu označí barevně ve sloupci Title width. Tyto titulky je dobré zkrátit, protože se nezobrazí ve vyhledávači celé, což by byla škoda.

Kromě délky titulků si můžete zkontrolovat i to, zda obsahují klíčová slova a zda jsou napsány věcně a poutavě pro uživatele, kteří vaši stránku mohou najít ve vyhledávači.
Optimalizace popisků
Podobný princip, jako u titulků, platí také u popisků. Měli byste se snažit, aby byly vaše popisky napsány věcně a poutavě, obsahovaly klíčová slova a nebyly příliš dlouhé nebo naopak příliš krátké. Rovněž se nedoporučuje mít jeden stejný popisek pro všechny URL webu.
Zároveň však nemusíte pro každou jednu stránku vytvářet meta popisek. Zaměřte se jen na důležité stránky webu nebo takové, které se zobrazují ve vyhledávačích na předních pozicích a vodí vám návštěvnost. Nevadí, pokud váš meta popisek zůstane prázdný.
Optimalizace H1 nadpisů
H1 nadpis je nadpis, který je viditelný nejen pro vyhledávače, ale také přímo na stránce očima čtenáře. Proto by měl být co nejvíce atraktivní a měl by vypovídat o tom, o čem je daná stránka. V ideálním případě by měl obsahovat klíčové slovo, na které stránky optimalizujete.
Co dalšího by vás mohlo zajímat ať už z pohledu vaší vlastní stránky nebo při analýze konkurence?
Vyplnění ALT textů
Dalším důležitým faktorem, na který byste se měli zaměřit, je to, zda máte pro obrázky vyplněné ALT texty. Jejich vyplněním pomůžete nejen uživatelům se zrakovým postižením, ale také sobě ve viditelnosti v obrázkovém vyhledávání Google Images.
Víc informací o ALT textu se dozvíte v tomto článku: https://help.marketingminer.com/cs/clanek/co-je-alt-text-tag-anebo-seo-pro-obrazky/.
Počet interních a externích odkazů na stránce
Těch by nemělo být příliš mnoho, ale ani příliš málo. Málo odkazů může znamenat, že obsah nemáte podložený dalšími zdroji. Příliš mnoho odkazů může naopak působit nedůvěryhodně a zároveň snižovat váhu důležitých stránek, na které odkazujete.
Počet komentářů
Vysoký počet komentářů u článku může indikovat úspěšnost článku. Pokud článek vyvolal v čtenářích potřebu reagovat, ať už negativní nebo pozitivní, pravděpodobně se jedná o dobrý obsah. Zaměřte se na analýzu tohoto obsahu a inspirujte se.
Informace o obsahu
Počet slov v článku je rovněž zajímavým indikátorem toho, jak dlouhé články, v průměru, vytváří vaše konkurence a jak dobře jejich délka funguje nebo naopak nefunguje.