Robots.txt je textový soubor, kterým můžete usměrnit, které webové stránky nebo soubory má robot (nejčastěji crawler vyhledávačů) procházet nebo neprocházet. Dobrým standardem je také uvádění umístění sitemap souborů v robots.txt.
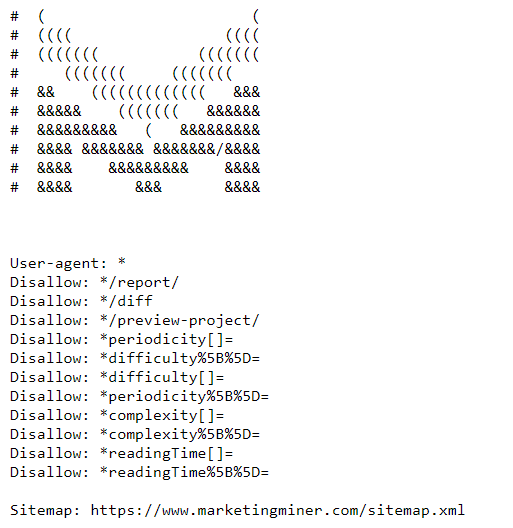
Níže vidíte ukázku MM souboru robots.txt, kterou najdete na této URL: https://www.marketingminer.com/robots.txt.
Vyzkoušejte Marketing Miner nyní:
Na co se používá robots.txt soubor?
Pomocí souboru robots.txt primárně zakazujete botům, aby se dostaly na specifické stránky/soubory a díky tomu vám boti nepřetěžují server a zároveň v případě vyhledávačů šetříte crawl budget na důležité stránky.
Hodně lidí používá robots.txt na prevenci před zaindexováním vstupních stránek (například administrace, citlivé údaje uživatelů…). Google však doporučuje v případě, že nechcete zaindexovat specifickou vstupní stránku, abyste raději využili direktivu noindex.
V případě použití noindex však nešetříte crawl budget, protože danou vstupní stránku musí crawler navštívit, aby až následně na ní objevil direktivu noindex.
Jak funguje robots.txt?
Primárním úkolem crawlerů vyhledávačů je procházení (crawling) webových stránek s cílem objevení obsahu, jeho zaindexování a následné zobrazování pro uživatele ve vyhledávači.
V první řadě, když se dostane crawler na webovou stránku, tak hledá soubor robots.txt, který by se měl nacházet v root adresáři webové stránky (čili dostupné na vase-domena.cz/robots.txt). V případě, že soubor robots.txt není vytvořený nebo se nenachází v root adresáři /robots.txt, tak má automaticky crawler přístup k procházení všech podstránek.
Bohužel ne všechny crawlery dodržují instrukce uvedené v robots.txt (např. různé scrapovací služby, které hledají e-maily a podobně).
Ukázka zápisu v robots.txt:
User-agent: jmeno-user-agenta
Disallow: URL, kterou chcete zakázat
Na praktické ukázce níže vidíte, že je pro Googlebota (název user-agenta crawlera od Google) zakázané procházení všech podstránek, které obsahují v URL /blog/.
User-agent: Googlebot
Disallow: /blog/
Níže najdete asi nejčastější zápis, se kterým se setkáte. Většina redakčních systémů má defaultně toto nastavení souboru robots.txt. Znamená to, že všichni user-agenti (to představuje ta hvězdička *) mohou procházet všechny vstupní stránky (v Disallow není nic zablokované):
User-agent: *
Disallow:
Naopak na zápis níže si dávejte velký pozor, protože představuje blokování přístupu robota na celý web (včetně domovské stránky).
User-agent: *
Disallow: /
Často se stane, že vývojáři zapomenou v robots.txt odstranit toto lomítko po nahození webu do produkce a lidé se potom diví, proč se jim nezačíná indexovat stránka.
Syntax robots.txt
V robots.txt platí následující syntax:
- User-agent: Na prvním řádku můžete zadat název user-agenta, pro kterého má platit dané omezení. Seznam nejpoužívanějších user-agentů najdete na tomto odkazu.
- Disallow: Na druhém řádku specifikujete, pro ktoré vstupní stránky chcete výše uvedenému user-agentovi zakázat procházení. Zadávat sem můžete pouze relativní cestu (ne absolutní).
- Allow: Tento příkaz akceptuje zatím jen Googlebot. Díky němu můžete povolit přístup na specifickou vstupní stránku, i když je například jeho nadřazený adresář zablokovaný přes Disallow.
- Crawl-delay: Tímto příkazem jste v minulosti mohli usměrnit crawlera, aby až po vámi specifikované době začal procházet vstupní stránky na webu. Tato hodnota se udávala v sekundách. Bohužel Google v roce 2019 přestal podporovat používání této direktivy.
- Sitemap: Jak jsme už výše uváděli, je dobrým standardem uvádět v souboru robots.txt také odkaz na vaše sitemapy, aby je crawler co nejdříve objevil.
Jak ověřit funkčnost robots.txt?
Pokud už máte vytvořený soubor robots.txt a potřebujete otestovat, zda jsou zablokované vstupní stránky, které chcete, aby byly zablokované, tak doporučujeme využít nástroj na otestování přímo od Google.
Robots testing tool v Google Search Console
Abyste mohli používat nástroj na testování souborů robots.txt od Google, musíte mít web přidaný a ověřený v Google Search Console. Následně najdete tento nástroj na této URL: https://www.google.com/webmasters/tools/robots-testing-tool?hl=cs
Vyberte doménu, pro kterou chcete přístupnost zkontrolovat, a následně se vám objeví váš soubor robots.txt, tak jak ho vidí Googlebot. Ve spodní části potom můžete vložit podstránku, pro kterou chcete zkontrolovat, zda je blokovaná nebo povolená. Vypadá to zhruba takto:
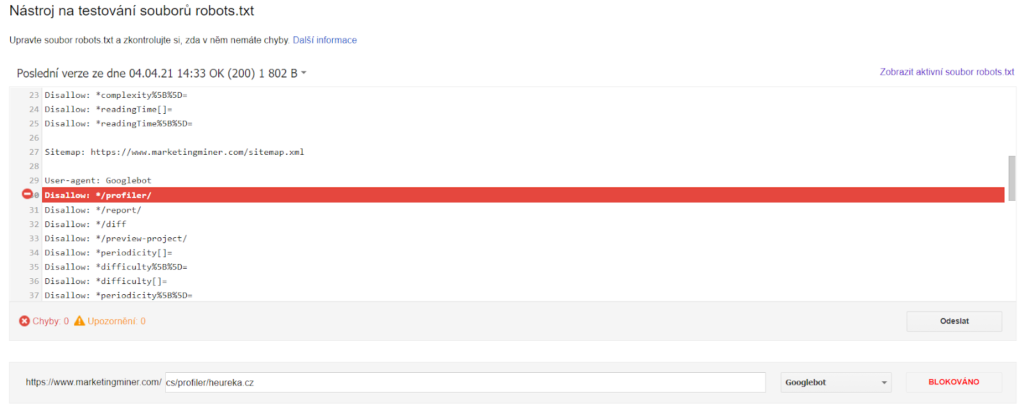
Na obrázku výše vidíte, že URL adresu https://www.marketingminer.com/cs/profiler/heureka.cz blokujeme v robots.txt.
URL Indexability v MM
Na hromadné zkontrolování blokace URL adres přes robots.txt můžete využít i Marketing Miner, a to konkrétně miner URL Indexability, který zkontroluje indexovatelnost vstupních stránek.
Videonávod na kontrolu indexace:
Závěr
Víc informací o souboru robots.txt najdete v dokumentaci od Google: https://developers.google.com/search/docs/advanced/robots/intro.