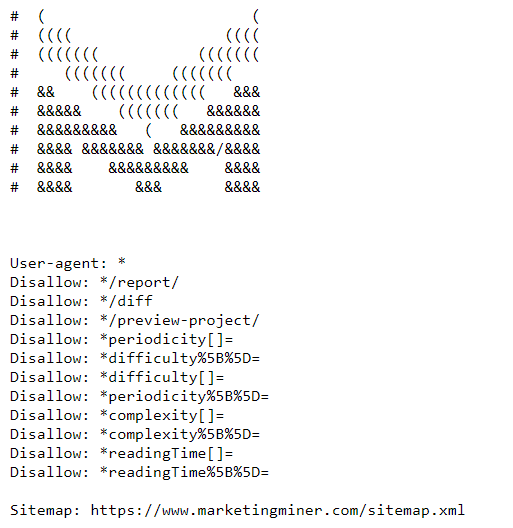
Robots.txt is a plain text file that tells web robots (most often search engine crawlers) which web pages or files can or cannot be crawled. It’s good practice to also include your sitemap location in the robots.txt file.
Here’s the example of the MM robots.txt file: https://www.marketingminer.com/robots.txt.
What is robots.txt used for?
By using robots.txt file, you prevent crawlers from accessing specific pages/files. It keeps your resources under control and it prevents overloading the server with bots. In addition, it also helps to optimize a crawl budget by allowing the crawling of important pages.
Many people use robots.txt to prevent search engine bots from indexing pages (e.g. admin pages, pages with sensitive information,…). Although, Google advises using a noindex directive for pages you don’t want to index in the search engine.
Remember, if you use the noindex tag on your site, it doesn’t help you save your crawl budget as the crawler still needs to visit the page to be able to discover the noindex directive.
How does robots.txt work?
The primary goal of search engine crawlers is to crawl web pages to discover content, index it, and then serve it to users in the search engines.
When the crawl attempts to visit a page, it automatically looks for your robots.txt file located in the root of the website (for example: https://www.marketingminer.com/robots.txt). If your robots.txt doesn’t exist or it isn’t located at the root of your website folder, the crawler will automatically check all your web pages.
Unfortunately the robots.txt directives are not supported by all crawlers (e.g. email address scrapers etc.). For this reason, it’s important to remember that some search engines ignore them completely.
Example robots.txt:
User-agent: user-agent-name
Disallow: pages you don't want to be crawled
In the example below, you can see that Googlebot (user-agent name) is restricted from accessing all pages that contain /blog/ string in the URL.
User-agent: Googlebot
Disallow: /blog/
Below, you can find the most common format of a robots.txt file. Most CMS programs already have a robots.txt file in place. It means that, all user agents (represented by an asterisk *) can crawl all pages (there is nothing blocked in the disallow section).
User-agent: *
Disallow:
Be careful with the command below, as this directive blocks all bots from crawling your site (even your homepage!).
User-agent: *
Disallow: /
It often happens that web developers forget to remove the slash from the disallow section in robots.txt file after putting the site live. And then many website owners are wondering why their site is not being indexed yet.
Robots.txt syntax
In the simple form, robots.txt file looks as follows:
- User-agent: The first line of every block of rules is the user-agent, which refers to the web crawler for which the directive has been written for. See the robots database for the most common user agents.
- Disallow: The second line specifies which parts of the website the designated user-agent can’t access. Only add relative paths, not absolute ones.
- Allow: At the moment, this directive is only accepted by Googlebot. It overrides disallow directives in the same robots.txt file. In this instance, crawlers are authorized to access specific pages even when their path was blocked by a disallow directive.
- Crawl-delay: Previously, you could use this directive to slow down crawling in order to not overload the server of your website. A crawl delay was specified in seconds. Unfortunately, Google stopped supporting this directive in 2019.
- Sitemap: As we previously mentioned, it’s good practice to include your sitemap location to the robots.txt file so crawlers can discover it as soon as possible.
How to validate your robots.txt file?
When your robots.txt file is ready and needs to be validated to ensure that search engines are crawling the right pages, we recommend you to use a testing tool created directly by Google.
The robots.txt Tester tool in Google Search Console
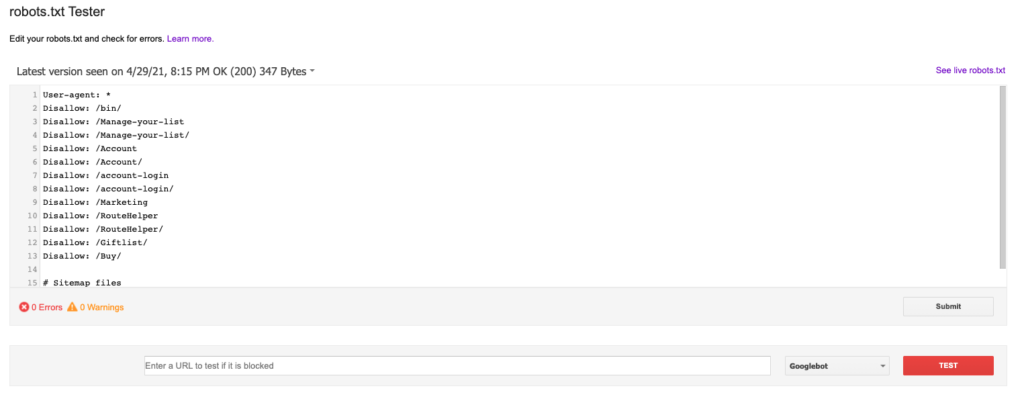
To be able to test your robots.txt file with the robots.txt tester, you need to add your website and verify the property in Google Search Console. You can find the robots.txt Tester tool here: https://www.google.com/webmasters/tools/robots-testing-tool
When you select what domain you want to check, you should be able to view the robots.txt file and review it for all errors or warnings. This is the latest version of your robots.txt file that Googlebot currently reads. Below the robots.txt, you can also test specific pages to see if they are blocked or not. It looks something like this:
URL Indexability miner
You can also check all blocked pages in bulk through robots.txt in Marketing Miner. We created a URL indexability miner to validate whether your pages have been indexed by search engines or not.
Conclusion
Find out more information about robots.txt files here: https://developers.google.com/search/docs/advanced/robots/intro.