Robots.txt je textový súbor, ktorým viete usmerniť, ktoré webové stránky alebo súbory má robot (najčastejšie crawler vyhľadávačov) prechádzať alebo neprechádzať. Dobrým štandardom je tiež uvádzanie umiestnenia sitemap súborov v robots.txt.
Nižšie vidíte ukážku MM súboru robots.txt, ktorú nájdete na tejto URL: https://www.marketingminer.com/robots.txt.
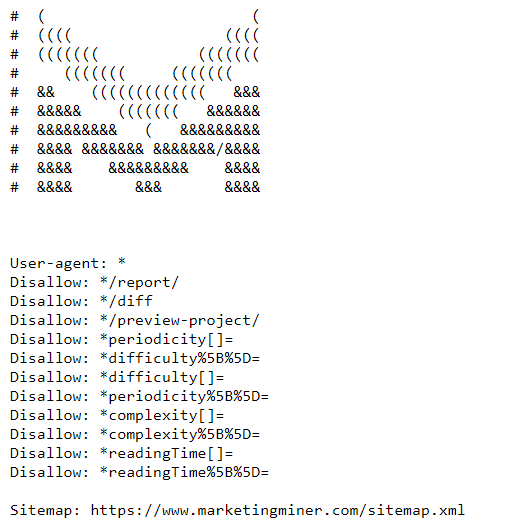
Na čo sa používa robots.txt súbor?
Pomocou súboru robots.txt primárne zakazujete botom, aby sa dostali na špecifické stránky/súbory a vďaka tomu vám boti nepreťažujú server a zároveň v prípade vyhľadávačov šetríte crawl budget na dôležité stránky.
Veľa ľudí používa robots.txt na prevenciu pred zaindexovaním vstupných stránok (napríklad administrácia, citlivé údaje používateľov…). Google však odporúča v prípade, že nechcete zaindexovať špecifickú vstupnú stránku, aby ste radšej využili direktívu noindex.
V prípade použitia noindex však nešetríte crawl budgetom, pretože danú vstupnú stránku musí crawler navštíviť, aby až následne na nej objavil direktívu noindex.
Ako funguje robots.txt?
Primárnou úlohou crawlerov vyhľadávačov je prechádzanie (crawling) webových stránok s cieľom objavenia obsahu, jeho zaindexovania a následného zobrazovania pre používateľov vo vyhľadávači.
V prvom rade, ako sa dostane crawler na webovú stránku, tak hľadá súbor robots.txt, ktorý by sa mal nachádzať v root adresári webovej stránky (čiže dostupné na vasa-domena.cz/robots.txt). V prípade, že súbor robots.txt nie je vytvorený alebo sa nenachádza v root adresári /robots.txt, tak má automaticky crawler prístup k prechádzaniu všetkých podstránok.
Bohužiaľ nie všetci crawleri dodržiavajú inštrukcie uvedené v robots.txt (napr. rôzne scrapovacie služby, ktoré hľadajú emaily a podobne).
Ukážka zápisu v robots.txt:
User-agent: meno-user-agenta
Disallow: URL, ktorú chcete zakázať
Na praktickej ukážke nižšie vidíte, že je pre Googlebota (názov user-agenta crawlera od Google) zakázané prechádzanie všetkých podstránok, ktoré obsahujú v URL /blog/.
User-agent: Googlebot
Disallow: /blog/
Nižšie nájdete asi najčastejší zápis, s ktorým sa stretnete. Väčšina redakčných systémov má defaultne takéto nastavenie súboru robots.txt. Znamená to, že všetci user-agenti (to predstavuje tá hviezdička *) môžu prechádzať všetky vstupné stránky (v Disallow nie je nič zablokované)
User-agent: *
Disallow:
Naopak na zápis nižšie, si dávajte veľký pozor, pretože predstavuje blokovanie prístupu robota na celý web (vrátane domovskej stránky).
User-agent: *
Disallow: /
Často sa stane, že vývojári zabudnú v robots.txt odstrániť toto lomítko po nahodení webu do produkcie a ľudia sa potom čudujú, prečo sa im nezačína indexovať stránka.
Syntax robots.txt
V robots.txt platí nasledujúca syntax:
- User-agent: Na prvom riadku viete zadať názov user-agenta, pre ktorého má platiť dané obmedzenie. Zoznam najpoužívanejších user-agentov nájdete na tomto odkaze.
- Disallow: Na druhom riadku špecifikujete, pre ktoré vstupné stránky chcete vyššie spomenutému user-agentovi zakázať prechádzanie. Zadávať sem môžete iba relatívnu cestu (nie absolútnu).
- Allow: Tento príkaz akceptuje zatiaľ iba Googlebot. Vďaka nemu viete povoliť prístup na špecifickú vstupnú stránku, aj keď je napríklad jeho nadradený adresár zablokovaný cez Disallow.
- Crawl-delay: Týmto príkazom ste v minulosti vedeli usmerniť crawlera, aby až po vami špecifikovanom čase, začal prechádzať vstupné stránky na webe. Táto hodnota sa udávala v sekundách. Bohužiaľ Google v roku 2019 prestal podporovať používanie tejto direktívy.
- Sitemap: Ako sme už vyššie spomínali, je dobrým štandardom uvádzať v súbore robots.txt aj odkaz na vaše sitemapy, aby ich crawler čím skôr objavil.
Ako overiť funkčnosť robots.txt?
Pokiaľ už máte vytvorený súbor robots.txt a potrebujete otestovať, či sú zablokované vstupne stránky, ktoré chcete, aby boli zablokované, tak odporúčame využiť nástroj na otestovanie priamo od Google.
Robots testing tool v Google Search Console
Aby ste mohli používať nástroj na testování souborů robots.txt od Google, musíte mať web pridaný a overený v Google Search Console. Následne nájdete tento nástroj na tejto URL: https://www.google.com/webmasters/tools/robots-testing-tool?hl=cs
Vyberte doménu, pre ktorú chcete prístupnosť skontrolovať a následne sa vám objaví vaš súbor robots.txt, tak ako ho vidí Googlebot. V spodnej časti potom viete vložiť podstránku, pre ktorú chcete skontrolovať či je blokovaná alebo povolená. Vyzerá to zhruba takto:
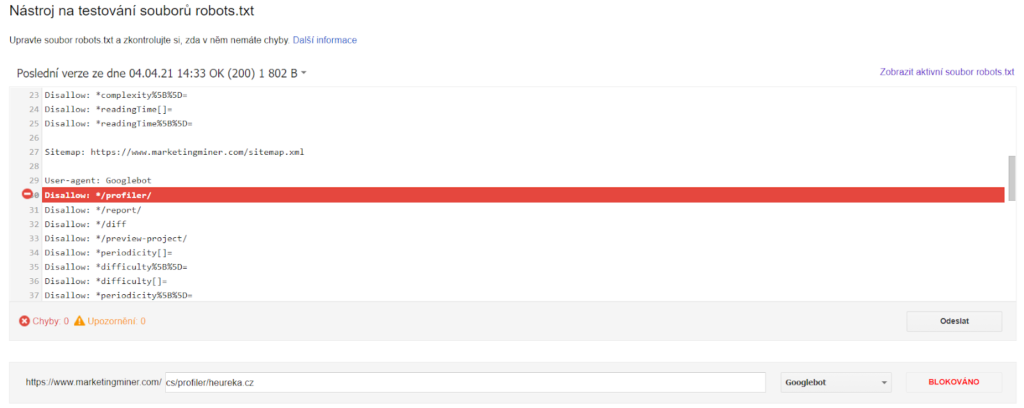
Na obrázku vyššie vidíte, že URL adresu https://www.marketingminer.com/cs/profiler/heureka.cz blokujeme v robots.txt.
URL Indexability v MM
Na hromadné skontrolovanie blokácie URL adries cez robots.txt môžete využiť aj Marketing Miner a to konkrétne miner URL Indexability, ktorý skontroluje indexovateľnosť vstupných stránok.
Videonávod na kontrolu indexácie:
Záver
Viac informácií o súbore robots.txt nájdete v dokumentácií od Google: https://developers.google.com/search/docs/advanced/robots/intro.