Content analysis analyzes a website’s content and its characteristics. It checks both the structure and length of the text as well as its key features, author details, readability, and other features.
In digital marketing, the content audit usually focuses on a specific content section of web pages, analyzing it in detail and identifying its weak/strong points, and possibly suggesting what direction you should take in creating new types of content.
Content analysis in Marketing Miner
Content Analysis Miner will help you analyze not only your own content, but also the content of your competitors. Find out the metadata (titles, descriptions) of any URL, the number of words or links on the web page.
Auditing your website
When analyzing your own site, you may want to focus on:
- Title -Is it too long or too short? Does it contain a keyword and is it attractive to a user searching on Google?
- Meta description – Is the description too long or too short? Does it include a keyword and is it attractive to a user searching on Google?
- Headline H1 – Does the H1 contain a keyword? Does the H1 correctly describe what the page is about and is it attractive to the user?
- Alt text – The total number of images on a page without alt text.
Reviewing your competitor’s website
When analyzing your competitor’s content, focus on their titles, descriptions and H1 headings. Mostly as you want to find out what keywords your competitor is optimizing for and what kind of content works well. In combination with Social signals miner, you can find out which of these articles are the most successful on social media too.
You can also look at other metrics, such as:
- Number of words per URL.
- Number of internal and external links on that URL.
- Article average reading time.
How to run a content audit in Marketing Miner
If you want to perform a complex content audit on any website, we recommend watching this video tutorial where we walk you through all the steps and show you the tools you can use to get the job done quickly.
How conduct Content Analysis in Marketing Miner
Start by clicking the Create report button and selecting the country you want data for and Content Analysis miner.
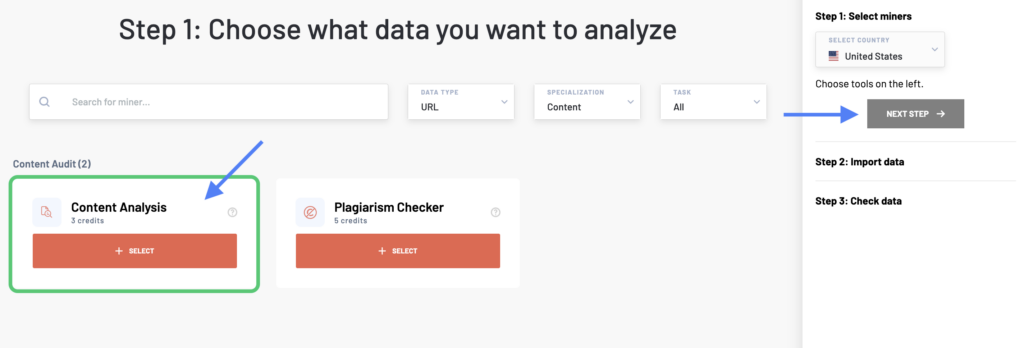
Name your report and add a list of URLs you want to check. You can either enter the list manually, upload a file or sitemap, or import your data from Google Analytics, Google Search Console, or Google Sheets.
You can easily use this tool to analyze all the URLs stored in your sitemap too. Just select the Import Data from URL option and enter your sitemap URL to upload it.
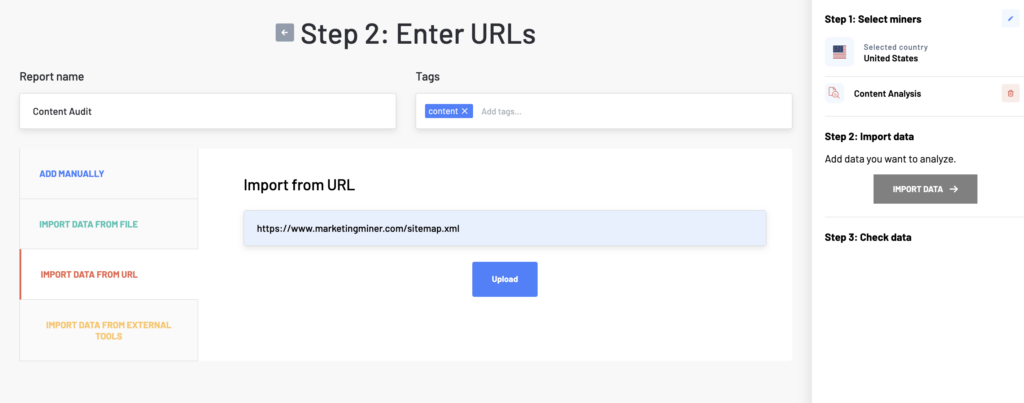
Then, click on Import Data to perform content analysis on your list of URLs. Once the report is generated, you will be emailed the analyzed data.
Content Analysis report example
Report columns
Let’s take a look at what data each column represents and how you can work with it. At the top of the report you will see a data visualization tab with Word Count Distribution and Images without ALT text to give you a quick overview of the data.
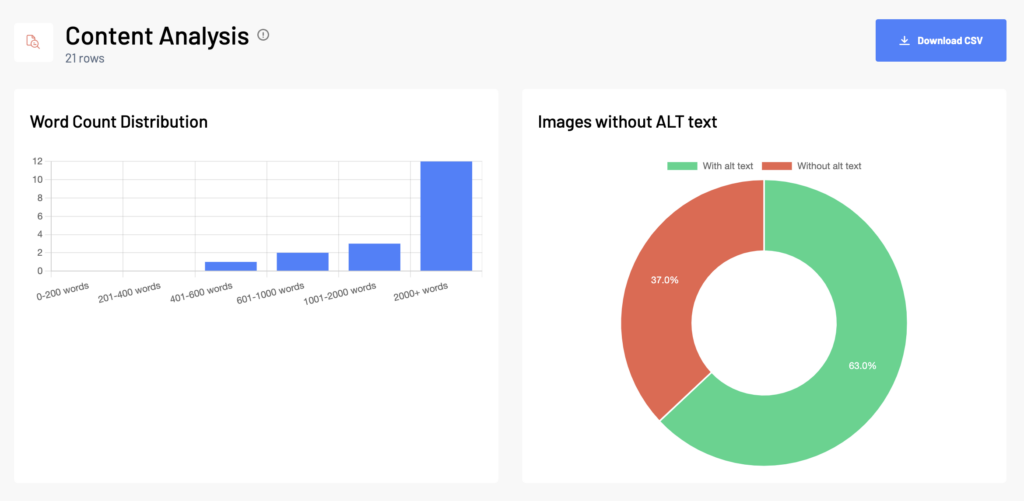
Content Analysis report
- Input: Analyzed URLs.
- Status: Status of the analyzed URL. If redirection or error occurs on the URL, the redirection or error status code is displayed in this column. More information about status codes can be found in the Status codes and redirects check guide.
- Meta description: Meta description of the page.
- H1: H1 heading of the page.
- Title: Title of the page.
- Title width: Title width in pixels.
- Number of images: number of images on the page.
- Images without alt text: how many images don’t have alternative text.
- Number of videos: number of videos on the page.
- Number of tables: number of tables on the page.
- Comments: Number of comments in the article.
Statistics
- Reading Time: Approximate time to read content on that URL. It is calculated based on the number of words in the content.
- Words: Number of words in the content.
- Paragraphs: The number of paragraphs in the content of that URL.
- Links: Number of internal and external links on the URL.
- Number of external links: Number of external links on the URL.
- Number of internal links: Number of internal links on the URL.
- Rel=”next”: Indicates whether there is the following page marking anywhere in the content with rel=”next”.
- Rel=”prev”: Indicates whether there is the previous page marking anywhere in the content with rel=”prev”.
Report data
When auditing your own content, focus on analyzing titles, descriptions, and H1 headings.
Title optimization
Marketing Miner will mark titles that are too long (over 600 px) in the report. You will see this information in the Title width column. It is better to shorten these titles, as they will be cut after 600 px in the search engine, which would be unfortunate.

In addition to the length of the title, you can also check if it contains important keywords and if it is written in a way that is appealing to users who might find your site in a search engine.
Meta description optimization
A similar approach to titles also applies to meta descriptions. You should try to write descriptions that are meaningful and compelling, that contain keywords, and that are neither too long nor too short. Having the same description for multiple URLs is also not recommended. However, you don’t have to create a unique meta description for every single page of your site. Just focus on important pages of the site or those that rank well and bring you traffic. It is okay if some meta descriptions are empty.
H1 optimization
H1 headline is a headline that is visible not only in the search engine, but also directly on the page and the reader can see it immediately. Therefore, it should be as attractive as possible and tell what the page is about. Ideally, it should contain a keyword that you are optimizing your site for.
What else might be interesting from the perspective of your own site or when analyzing your competition?
Adding alt text to images
Another factor that you should pay attention to is adding alt text to your images. By adding alt text to your images, you help not only visually impaired people but also the visibility of your website in image search results.
You can read more about alt text here: https://help.marketingminer.com/en/article/image-seo-what-is-alt-text-and-why-should-you-use-it/.
Number of internal and external links per page
There should be neither too many nor too few. Few links can mean that your content is not well supported by other sources. Too many links can appear untrustworthy and you will also get less link juice.
Number of comments
A high number of comments on the article may indicate the success of the article. If the article has caused readers to react, whether negatively or positively, it is likely to be quality content. Focus on analyzing this content and get inspired.
Content Information
The number of words in the article is also an interesting indicator of how long your competitor’s articles are on average, and how well their length works or does not work.