A Robots.txt egy egyszerű szöveges fájl, amely megmondja a webrobotoknak (leggyakrabban a keresőmotorok lánctalpasainak), hogy mely weboldalakat vagy fájlokat lehet és melyeket nem lehet feltérképezni. Jó gyakorlat, ha a robots.txt fájlban is szerepel a webhelytérkép helye.
Íme egy példa az MM robots.txt fájlra: https://www.marketingminer.com/robots.txt.
Mire használják a robots.txt-t?
A robots.txt fájl használatával megakadályozhatja, hogy a lánctalpasok hozzáférjenek bizonyos oldalakhoz/fájlokhoz. Ez kordában tartja az erőforrásokat, és megakadályozza a szerver túlterhelését botokkal. Ezenkívül a fontos oldalak feltérképezésének lehetővé tételével segít a feltérképezési költségvetés optimalizálásában is.
Sokan használják a robots.txt állományt, hogy megakadályozzák a keresőmotorok botjait az oldalak indexelésében (pl. admin oldalak, érzékeny információkat tartalmazó oldalak,…). Bár a Google azt tanácsolja, hogy használjon noindex direktívát azoknál az oldalaknál, amelyeket nem szeretne indexelni a keresőmotor.
Ne feledje, hogy ha a noindex taget használja a webhelyén, az nem segít megtakarítani a lánctalálási költségvetést, mivel a lánctalálóknak továbbra is meg kell látogatniuk az oldalt, hogy felfedezhessék a noindex direktívát.
Hogyan működik a robots.txt?
A keresőmotorok lánctalpas programjainak elsődleges célja a weboldalak feltérképezése a tartalom feltárása, indexelése, majd a felhasználók számára történő kiszolgálása a keresőmotorokban.
Amikor a crawl megpróbál meglátogatni egy oldalt, automatikusan megkeresi a robots.txt fájlt, amely a weboldal gyökerében található (például: https://www.marketingminer.com/robots.txt). Ha a robots.txt nem létezik, vagy nem a webhely mappájának gyökerében található, a lánctalpas program automatikusan ellenőrzi az összes webhelyét.
Sajnos a robots.txt direktívákat nem minden lánctalpas program támogatja (pl. az e-mail címeket lekaparók stb.). Ezért fontos megjegyezni, hogy egyes keresőmotorok teljesen figyelmen kívül hagyják őket.
Példa robots.txt:
User-agent: user-agent-name
Disallow: pages you don't want to be crawled
Az alábbi példában látható, hogy a Googlebot (a felhasználó-ügynök neve) nem férhet hozzá minden olyan oldalhoz, amelynek URL-címében szerepel a /blog/ karakterlánc.
User-agent: Googlebot
Disallow: /blog/
Az alábbiakban a robots.txt fájl leggyakoribb formátumát találja. A legtöbb CMS program már rendelkezik robots.txt fájlokkal. Ez azt jelenti, hogy az összes ( csillaggal * jelzett) felhasználó-ügynök minden oldalt átnézhet (a tiltó szakaszban nincs semmi blokkolva).
User-agent: *
Disallow:
Legyen óvatos az alábbi paranccsal, mivel ez az utasítás megakadályozza, hogy a botok feltérképezzék az oldalát (még a kezdőlapot is!).
User-agent: *
Disallow: /
Gyakran előfordul, hogy a webfejlesztők elfelejtik eltávolítani a slash-t a robots.txt fájl disallow szakaszából, miután élesítették a webhelyet. És akkor sok weboldal-tulajdonos csodálkozik, hogy miért nem indexelik még az oldalukat.
Robots.txt szintaxis
Egyszerű formában a robots.txt fájl a következőképpen néz ki:
- Felhasználó-ügynök: A szabályblokkok első sora a user-agent, amely arra a webes lánctalpasra utal, amely számára az utasítás íródott. A leggyakoribb felhasználói programokért lásd a robotok adatbázisát.
- Letiltás: A második sor meghatározza, hogy a weboldal mely részeihez nem férhet hozzá a kijelölt felhasználó-ügynök. Csak relatív elérési utakat adjon hozzá, abszolútakat ne.
- Engedélyezd: Jelenleg ezt az irányelvet csak a Googlebot fogadja el. Ez felülírja az ugyanabban a robots.txt fájlban található tiltó irányelveket. Ebben az esetben a lánctalpasok akkor is hozzáférhetnek bizonyos oldalakhoz, ha az elérési útvonalukat egy disallow utasítással blokkolták.
- Kúszás-késleltetés: Korábban ezzel az utasítással lelassíthatta a lánctalpasítást, hogy ne terhelje túl a weboldal szerverét. A kúszási késleltetést másodpercben adták meg. Sajnos a Google 2019-ben leállította ennek az irányelvnek a támogatását.
- Oldaltérkép: Ahogy korábban említettük, jó gyakorlat, ha a robots.txt fájlba beilleszted a webhelytérképed helyét, hogy a lánctalpasok a lehető leghamarabb felfedezhessék azt.
Hogyan érvényesítse a robots.txt fájlt?
Ha a robots.txt fájl készen van, és validálni kell, hogy a keresőmotorok a megfelelő oldalakat lássák, javasoljuk, hogy használja a közvetlenül a Google által létrehozott tesztelő eszközt.
A robots.txt tesztelő eszköz a Google Search Console-ban
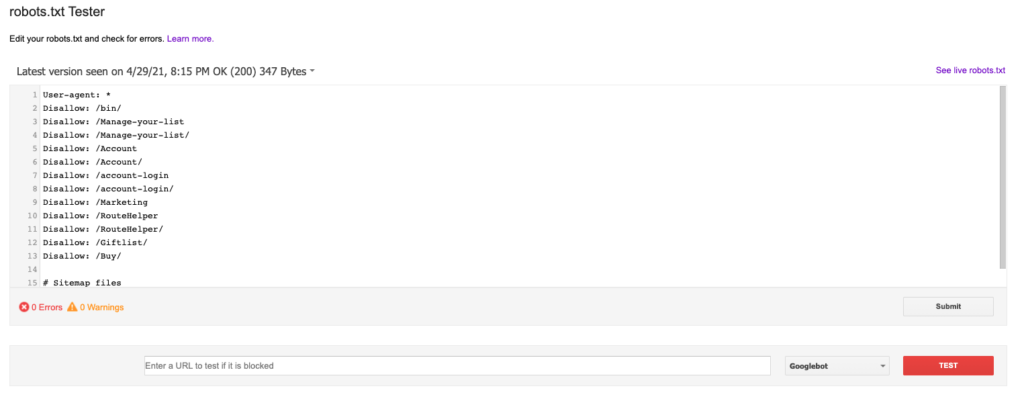
Ahhoz, hogy a robots.txt fájlt a robots.txt teszterrel tesztelhesse, hozzá kell adnia a webhelyét, és ellenőriznie kell a tulajdonságot a Google Search Console-ban. A robots.txt Tester eszközt itt találja: https://www.google.com/webmasters/tools/robots-testing-tool
Amikor kiválasztja, hogy melyik tartományt szeretné ellenőrizni, meg kell tudnia tekinteni a robots.txt fájlt, és átnézni az összes hibát vagy figyelmeztetést. Ez a robots.txt fájl legfrissebb verziója, amelyet a Googlebot jelenleg olvas. A robots.txt alatt tesztelheti az egyes oldalakat, hogy azok blokkolva vannak-e vagy sem. Valahogy így néz ki:
URL indexelhetőség bányász
A Marketing Minerben a robots.txt fájlon keresztül ömlesztve is ellenőrizheti az összes blokkolt oldalt. Létrehoztunk egy URL-indexálhatósági bányászprogramot, amely ellenőrzi, hogy a keresőmotorok indexelték-e az oldalaidat vagy sem.
Következtetés
A robots.txt fájlokkal kapcsolatos további információkat itt talál: https://developers.google.com/search/docs/advanced/robots/intro.