Robots.txt to zwykły plik tekstowy, który mówi robotom internetowym (najczęściej raczkującym w wyszukiwarkach), które strony internetowe lub pliki mogą, a które nie mogą być raczkowane. Dobrą praktyką jest również umieszczenie lokalizacji sitemapy w pliku robots.txt.
Oto przykład pliku MM robots.txt: https://www.marketingminer.com/robots.txt.
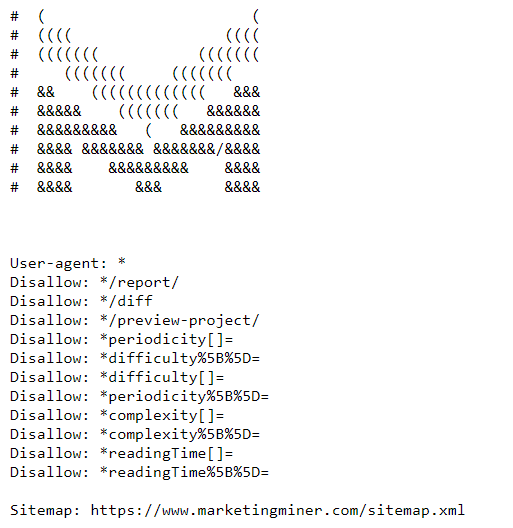
Do czego służy plik robots.txt?
Używając pliku robots.txt, uniemożliwiasz rakarzom dostęp do określonych stron/plików. Dzięki temu masz pod kontrolą swoje zasoby i nie dopuszczasz do przeciążenia serwera botami. Ponadto pomaga również zoptymalizować budżet na indeksowanie, umożliwiając indeksowanie ważnych stron.
Wiele osób używa robots.txt, aby zapobiec indeksowaniu stron przez boty wyszukiwarek (np. strony administratorów, strony z wrażliwymi informacjami,…). Chociaż Google radzi używać dyrektywy noindex dla stron, których nie chcesz indeksować w wyszukiwarce.
Pamiętaj, że jeśli użyjesz tagu noindex na swojej stronie, nie pomoże Ci to zaoszczędzić budżetu na indeksowanie, ponieważ crawler nadal musi odwiedzić stronę, aby móc odkryć dyrektywę noindex.
Jak działa robots.txt?
Podstawowym celem robotów indeksujących w wyszukiwarkach jest przeszukiwanie stron internetowych w celu odkrycia treści, indeksowania ich, a następnie serwowania ich użytkownikom w wyszukiwarkach.
Kiedy crawl próbuje odwiedzić stronę, automatycznie szuka Twojego pliku robots.txt znajdującego się w korzeniu witryny (na przykład: https://www.marketingminer.com/robots.txt). Jeśli twój robots.txt nie istnieje lub nie znajduje się w głównym folderze twojej strony, crawler automatycznie sprawdzi wszystkie twoje strony internetowe.
Niestety dyrektywy robots.txt nie są obsługiwane przez wszystkie crawlery (np. skrobaczki adresów e-mail itp.). Z tego powodu warto pamiętać, że niektóre wyszukiwarki całkowicie je ignorują.
Przykładowy plik robots.txt:
User-agent: user-agent-name
Disallow: pages you don't want to be crawled
W poniższym przykładzie widać, że Googlebot (nazwa user-agenta) ma ograniczony dostęp do wszystkich stron, które w adresie URL zawierają ciąg /blog/.
User-agent: Googlebot
Disallow: /blog/
Poniżej przedstawiamy najczęściej spotykany format pliku robots.txt. Większość programów CMS posiada już plik robots.txt. Oznacza to, że wszystkie agenty użytkownika (reprezentowane przez gwiazdkę *) mogą przeglądać wszystkie strony (nie ma nic zablokowanego w sekcji disallow).
User-agent: *
Disallow:
Uważaj na poniższe polecenie, ponieważ dyrektywa ta blokuje wszystkim botom możliwość indeksowania Twojej witryny (nawet strony głównej!).
User-agent: *
Disallow: /
Często zdarza się, że twórcy stron internetowych zapominają o usunięciu ukośnika z sekcji disallow w pliku robots.txt po uruchomieniu witryny. A potem wielu właścicieli stron internetowych zastanawia się, dlaczego ich strona nie jest jeszcze indeksowana.
Składnia pliku robots.txt
W prostej formie plik robots.txt wygląda następująco:
- User-agent: W pierwszej linii każdego bloku reguł znajduje się user-agent, który odnosi się do crawlera internetowego, dla którego dana dyrektywa została napisana. Zobacz bazę danych robotów dla najbardziej popularnych agentów użytkownika.
- Disallow: Druga linia określa, do których części witryny wskazany user-agent nie ma dostępu. Dodawaj tylko ścieżki względne, a nie bezwzględne.
- Allow: W tej chwili ta dyrektywa jest akceptowana tylko przez Googlebota. Nadpisuje on dyrektywy disallow w tym samym pliku robots.txt. W tym przypadku crawlery są upoważnione do dostępu do określonych stron, nawet jeśli ich ścieżka została zablokowana przez dyrektywę disallow.
- Crawl-delay: Wcześniej można było użyć tej dyrektywy, aby spowolnić indeksowanie, aby nie przeciążyć serwera swojej witryny. Opóźnienie pełzania zostało określone w sekundach. Niestety, Google przestało wspierać tę dyrektywę w 2019 roku.
- Sitemap: Jak już wcześniej wspomnieliśmy, dobrą praktyką jest dołączenie lokalizacji twojej sitemapy do pliku robots.txt, aby roboty indeksujące mogły ją odkryć jak najszybciej.
Jak sprawdzić poprawność pliku robots.txt?
Kiedy Twój plik robots.txt jest gotowy i wymaga walidacji, aby upewnić się, że wyszukiwarki indeksują właściwe strony, zalecamy skorzystanie z narzędzia testującego stworzonego bezpośrednio przez Google.
Narzędzie robots.txt Tester w Google Search Console
Aby móc przetestować plik robots.txt za pomocą testera robots.txt, należy dodać swoją stronę i zweryfikować właściwość w Google Search Console. Narzędzie do testowania robots.txt można znaleźć tutaj: https://www.google.com/webmasters/tools/robots-testing-tool
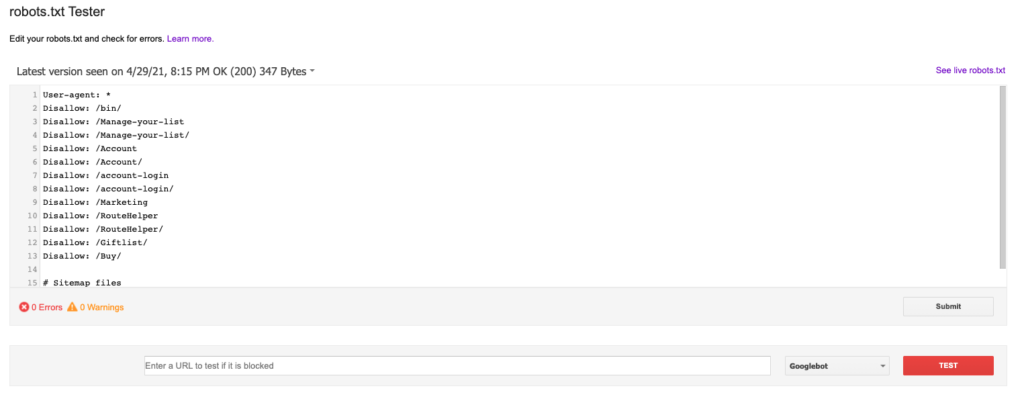
Po wybraniu domeny, którą chcesz sprawdzić, powinieneś być w stanie zobaczyć plik robots.txt i przejrzeć go pod kątem wszystkich błędów lub ostrzeżeń. Jest to najnowsza wersja Twojego pliku robots.txt, którą Googlebot aktualnie czyta. Poniżej robots.txt można również przetestować konkretne strony, aby sprawdzić, czy są one zablokowane, czy nie. Wygląda to mniej więcej tak:
URL Indexability Miner
Możesz również sprawdzić wszystkie zablokowane strony hurtowo poprzez robots.txt w Marketing Miner. Stworzyliśmy Sprawdzanie indeksowalności adresów URL miner, aby sprawdzić, czy Twoje strony zostały zaindeksowane przez wyszukiwarki, czy nie.
Wniosek
Więcej informacji o plikach robots.txt znajdziesz tutaj: https://developers.google.com/search/docs/advanced/robots/intro.